

BSA04_Audio.ipynb
필요한 패키지
import wave # 표준패키지
import os # 폴더 변경 등의 작업에 사용
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import seaborn as sns
import librosa
import librosa.display
from glob import glob
from scipy.fft import fft, dct, ifft, idct
첫 번째 파일 읽고 재생하기
os.chdir("D:\Bigdata\RAVDESS\Actor_01")
음성파일 = "03-01-01-01-01-01-01.wav"
음성1 = wave.open("03-01-01-01-01-01-01.wav", "r")
print(음성1.getnchannels()) # mono (channel=1개)
print(음성1.getsampwidth()) # 2 byte
print(음성1.getframerate()) # 1초에 48000번
print(음성1.getnframes()) # 전체적으로 158558의 데이터가 있음
print(음성1.getparams())
display(Audio(음성파일))
여러 음성 파일을 하나의 리스트로 묶기
음성묶음 = glob("D:\Bigdata\RAVDESS\*\*.wav") # 사람별로 음성파일을 다 가져와서 묶기
print(음성묶음[0])
display(Audio(음성묶음[0]))
첫 번째 음성파일 시각적으로 표시하기
sns.set_theme(style="white", palette=None)
color_pal = plt.rcParams['axes.prop_cycle'].by_key()['color']
음성자료, 표집률 = librosa.load(음성묶음[0])
## 음성자료 : nparray
print(f'음성자료:{음성자료[:10]}')
print(f'형태:{음성자료.shape}')
print(f'표집률:{표집률}')
## 시계열 그림
pd.Series(음성자료).plot(figsize=(10,5), lw=1, title="Raw Audio Data", color=color_pal[0]) # line width (lw=1)
plt.show()
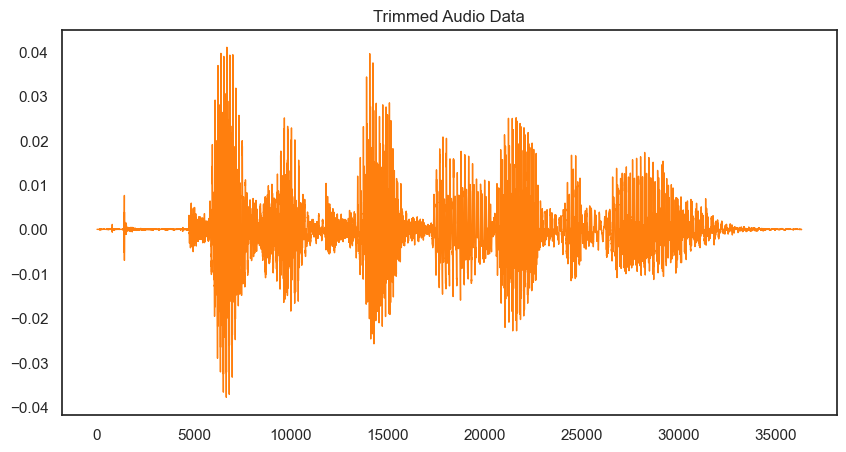
# -> 불필요한 부분을 확인할 수 있음
유의음성, _ = librosa.effects.trim(음성자료, top_db=50) # 불필요한 부분을 자르는 작업
pd.Series(유의음성).plot(figsize=(10,5), lw=1, title="Trimmed Audio Data", color=color_pal[1])
plt.show()
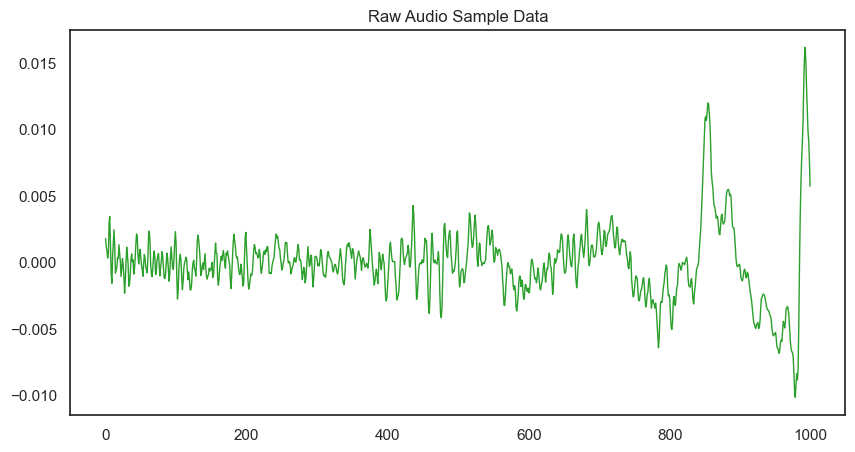
# 1000개의 데이터를 그림으로 그리는 작업
pd.Series(음성자료[30000:31000]).plot(figsize=(10,5), lw=1, title="Raw Audio Sample Data", color=color_pal[2])
plt.show()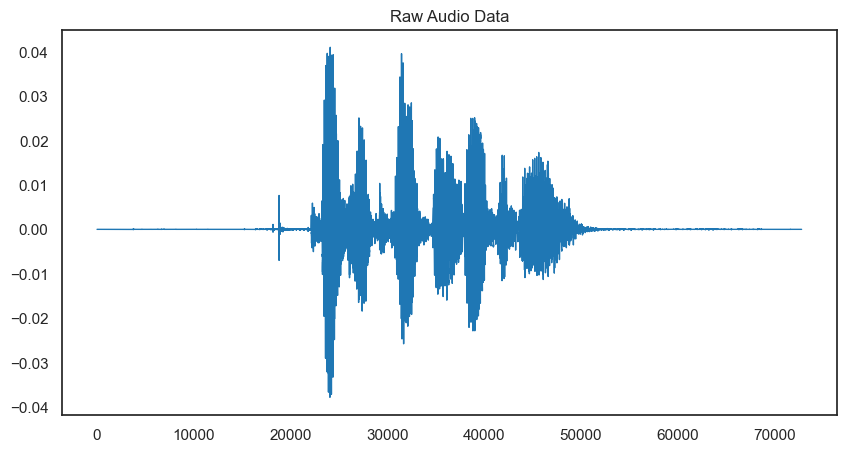
Spectrogram
# stft : a signal in the time-frequency domain by computing discrete Fourier transforms(DFT) over short overlapping windows
# amplitude_to_db : Convert an amplitude spectrogram to dB-scaled spectrogram
변환자료 = librosa.stft(음성자료)
변환dB = librosa.amplitude_to_db(np.abs(변환자료),ref=np.max)
변환dB.shape
# Plot the transformed audio data
fig, ax = plt.subplots(figsize=(10,5))
이미지 = librosa.display.specshow(변환dB, x_axis="time", y_axis="log", ax=ax)
ax.set_title("Spectrogram example", fontsize=20)
fig.colorbar(이미지, ax=ax, format=f'%0.1f')
plt.show()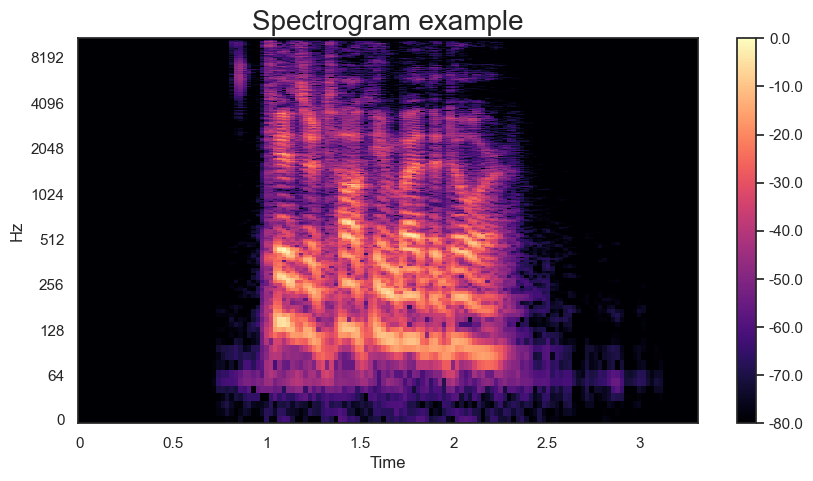
DCT, IDCT
# DCT, IDCT
from scipy.fft import fft, dct, ifft, idct
음성FFT = fft(음성자료).real
음성DCT = dct(음성자료, 1)
역음성FFT = ifft(음성FFT).real
역음성DCT = idct(음성DCT, 1)
'Statistics > BSA' 카테고리의 다른 글
| 230410 / BSA05. 데이터 전처리 2 : python에서 결측값 처리 (0) | 2023.04.14 |
|---|---|
| 230405 / BSA05. 데이터 전처리 (0) | 2023.04.10 |
| 230329 / BSA04. 다양한 형식의 데이터 파일 읽고 저장하기 (0) | 2023.04.02 |
| 230327 / BSA04. 다양한 형태의 자료 파일 작업 속도 비교 (0) | 2023.04.02 |
| 230322 / BSA03. 데이터 분석 주요 과정 살펴보기 (0) | 2023.03.26 |