

1. 코드
%matplotlib inline import pandas as pd import seaborn as sns
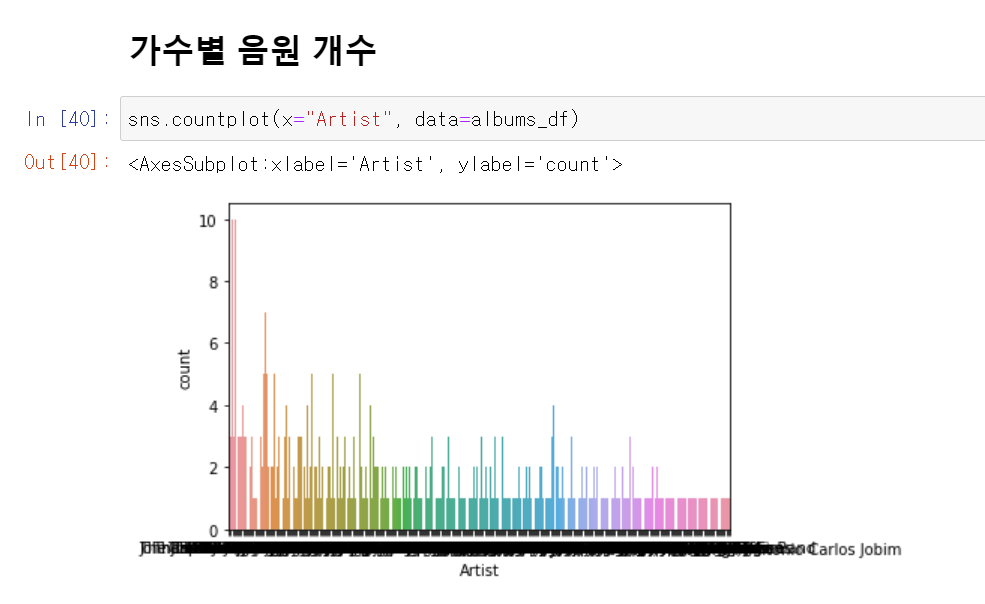
1. countplot을 이용해 그룹별로 count
sns.countplot(x="Artist", data=albums_df)seaborn.countplot — seaborn 0.11.1 documentation
Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters.
seaborn.pydata.org
2. kdeplot
sns.kdeplot(albums_df['Year'])seaborn.kdeplot — seaborn 0.11.1 documentation
Orientation parameter. Deprecated since version 0.11.0: specify orientation by assigning the x or y variables.
seaborn.pydata.org
3. violinplot
ax = sns.violinplot(x="Year", y="Genre", data=albums_df)seaborn.violinplot — seaborn 0.11.1 documentation
The method used to scale the width of each violin. If area, each violin will have the same area. If count, the width of the violins will be scaled by the number of observations in that bin. If width, each violin will have the same width.
seaborn.pydata.org
2. 발견한 인사이트
1. 가장 많은 음원을 낸 가수는 'The Rolling Stones', 'The Beatles', 'Bob Dylan', 'Bruce Springsteen', 'The Who', 'Radiohead', 'David Bowie', 'Various Artists', 'Elton John', 'Led Zeppelin' 순서임을 알 수 있음

2. 가장 많은 음원이 발표된 해는 1970년대임을 알 수 있음

3. 연도별 가장 많이 발표된 음원 장르를 파악하려 했지만 데이터가 많아 파악하기 어려웠음 -> 1910s, 1920s,... 이렇게 묶어야 되나(??)

4. 가장 많이 발표된 음원 장르 10개는 'Rock', 'Funk/Soul', 'Hip Hop', 'Electronic, Rock', 'Rock, Pop', 'Rock, Blues', 'Folk, World, & Country', 'Rock, Folk, World, & Country', 'Blues', 'Jazz' 임을 알 수 있음

3. 한 줄 평가
- 항목이 많은 경우에 그래프로 나타내면 항목 이름이 겹쳐서 제대로 보이지 않는 경우에 해결하는 방법을 알고 싶음

- 장르별로 ', ' 나 '/', '&' 기준으로 split 해서 그룹화하고 싶었으나 그러기에는 데이터의 특성이 사라지는 것 같아 더 나은 방법을 알고 싶음


- 연도별 주로 발표된 음원 장르 시각화(??)
+++
5. 10년씩 묶어서 그래프로 나타낸 결과

-> 2보다 정확하게 연도별 발매 음원 수를 파악할 수 있음

-> 연도별로 주로 발매된 음원 장르
-> 1950년대 데이터도 10개밖에 없어 유의미한 결과를 얻어내기에는 데이터가 부족하지만 주로 'Jazz', 'Blues' 음악이 많았음을 알 수 있음

-> 1960년대는 'Rock', 'Rock, Blues', 'Funk / Soul'이 많음

-> 1970년대는 'Rock', 'Funk / Soul', 'Rock, Pop'이 많음

-> 1980년대는 'Rock', 'Hip Hop', 'Funk / Soul, Pop', 'Rock, Pop'이 많음

-> 1990년대는 'Rock', 'Hip Hop', 'Electronic, Rock'이 많음

-> 2000년대는 'Rock', 'Hip Hop', 'Electronic, Rock'이 많음

-> 2010년대는 데이터가 2개밖에 없어서 유의미한 결과를 얻어내기에는 데이터가 부족함
-> 연도별로 새로 생겨난 장르나 가장 많이 발매된 음원 장르 3개의 변화를 그래프로 시각화하는 방법(??)
'DA' 카테고리의 다른 글
| #17. occupations.csv (0) | 2021.07.21 |
|---|---|
| #16. museum_1.csv / museum_2.csv / museum_3.csv (0) | 2021.07.21 |
| #14. salaries.csv (0) | 2021.07.20 |
| #13. insurance.csv (0) | 2021.07.20 |
| #12. starbucks_drinks.csv (0) | 2021.07.20 |