

1. 코드
%matplotlib inline import pandas as pd import seaborn as sns
1. 특정 문자열을 포함하고 있는지 확인하기
museum_1['시설명'].str.contains('대학')
2. 문자열을 특정 문자를 기준으로 분리해 새로운 칼럼 생성하기
number = museum_2['운영기관전화번호'].str.split(pat='-', n=2, expand=True) museum_2['지역번호'] = number[0]
3. 칼럼명 변경하기 (inplace=True)
museum_2.rename(columns={"지역번호": "지역명"}, inplace=True)2. 발견한 인사이트
1. '시설명' column에서 '대학교'를 포함한 데이터는 '대학'으로, 그렇지 않으면 '일반'으로 분류하여 '분류' 칼럼 추가
-> '일반' 박물관이 814개, '대학' 박물관이 86개로 '일반' 박물관이 더 많은 것을 알 수 있음


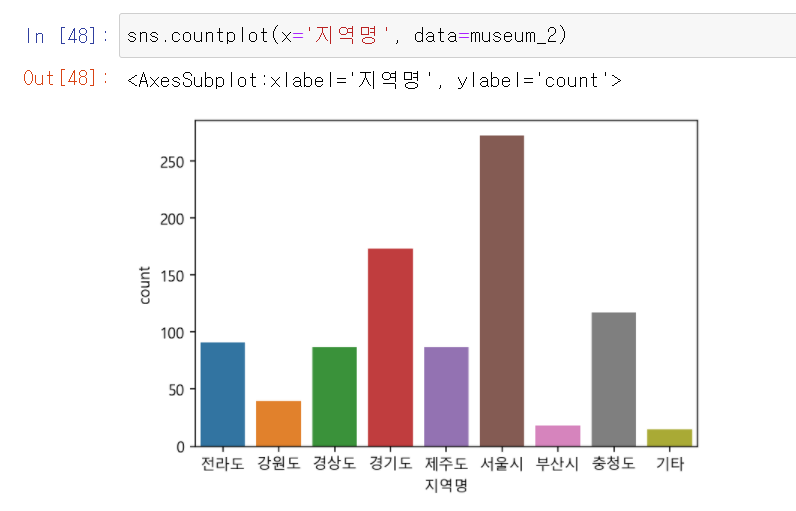
2. 지역별 museum 수를 나타낸 결과, '서울시', '경기도', '충청도' 순서로 많은 것을 알 수 있음
3. 대학 박물관/미술관은 '서울시'에 가장 많은 것을 알 수 있음

3. 한 줄 평가
- map 메소드를 이용해 지역번호를 기준으로 지역명 칼럼을 추가하는 부분이 어려웠음

cf. jupyter notebook 그래프 한글 깨짐 현상 해결
# 사용자 운영체제 확인 import platform platform.system() # 파이썬 시각화 패키지 불러오기 import matplotlib.pyplot as plt %matplotlib inline if platform.system() == 'Darwin': # Mac 환경 폰트 설정 plt.rc('font', family='AppleGothic') elif platform.system() == 'Windows': # Windows 환경 폰트 설정 plt.rc('font', family='Malgun Gothic') plt.rc('axes', unicode_minus=False) # 마이너스 폰트 설정 # 글씨 선명하게 출력하는 설정 %config InlineBackend.figure_format = 'retina''DA' 카테고리의 다른 글
| #18. parks.csv (0) | 2021.07.22 |
|---|---|
| #17. occupations.csv (0) | 2021.07.21 |
| #15. albums.csv (0) | 2021.07.21 |
| #14. salaries.csv (0) | 2021.07.20 |
| #13. insurance.csv (0) | 2021.07.20 |